IREX - Audio_Learning
Depuis la fin des années 90, l’apprentissage profond, avec les CNN, RNN et autoencodeurs, révolutionne la reconnaissance vocale, musicale et la détection sonore.
Introduction
Historique
Architecture des CNN
Méthodes d'apprentissage profond utilisant des CNN
Conclusion
Illustration Vidéo
Voir aussi
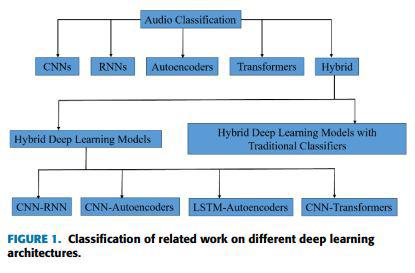
1.Introduction
La classification audio joue un rôle essentiel dans l’amélioration de la vie quotidienne en rendant la reconnaissance vocale plus précise pour le contrôle sans contact - bénéfique aux personnes à mobilité réduite – aux assistants vocaux, maisons intelligentes et systèmes de sécurité. Elle permet d’identifier la parole, la musique ou les sons environnementaux pour des applications variées : détection d’intrus, reconnaissance musicale, classification de sons ambiants. Si les méthodes traditionnelles (SVM, KNN, HMM) ont longtemps dominé, l’apprentissage profond s’impose aujourd’hui grâce à sa capacité à détecter des motifs complexes sans extraction manuelle. CNN, RNN, autoencodeurs, transformers et modèles hybrides offrent une précision supérieure, mais requièrent des données massives et une puissance de calcul importante. Convertissant les signaux en spectrogrammes ou en coefficients MFCC, ces modèles optimisent des tâches comme la reconnaissance vocale, l’identification des locuteurs et la segmentation audio.
2. Historique
L’évolution de la classification audio avec l’intelligence artificielle remonte aux années 1950. En 1952, les Bell Labs développent Audrey, le premier système de reconnaissance vocale capable d’identifier les chiffres de zéro à neuf. Durant les années 1960 et 1970, les modèles de Markov cachés (HMM) deviennent la norme pour modéliser la nature séquentielle des signaux vocaux, tandis que l’extraction manuelle de caractéristiques, comme les coefficients cepstraux en fréquence Mel (MFCC), se généralise.
Dans les années 1980, les algorithmes classiques tels que les k-plus proches voisins (KNN) et les machines à vecteurs de support (SVM) sont largement utilisés pour la classification audio. En 1989, Yann LeCun introduit les réseaux de neurones convolutionnels (CNN), marquant un tournant vers l’apprentissage automatique plus avancé.
En 1990, la mise à disposition de bases de données audio telles que TIMIT permet de standardiser l’entraînement et l’évaluation des systèmes de reconnaissance vocale. En 1998, les CNN commencent à être appliqués à la reconnaissance vocale, ouvrant la voie à des approches plus performantes.
Les années 2000 voient l’intégration des réseaux de neurones récurrents (RNN) pour capturer la dépendance temporelle des signaux audio. À partir de 2010, l’essor du deep learning, favorisé par la puissance des GPU, transforme profondément la classification audio. En 2014, les architectures LSTM et les autoencodeurs gagnent en popularité pour la reconnaissance et la séparation des sources sonores.
En 2017, l’apparition des Transformers révolutionne le traitement des données séquentielles, y compris l’audio, grâce à leur capacité à modéliser des relations à longue portée. Depuis 2020, les modèles hybrides combinant CNN, RNN et Transformers offrent des performances inégalées, soutenant des applications variées allant des assistants vocaux aux systèmes de sécurité en passant par la santé.
3. Architecture des CNN
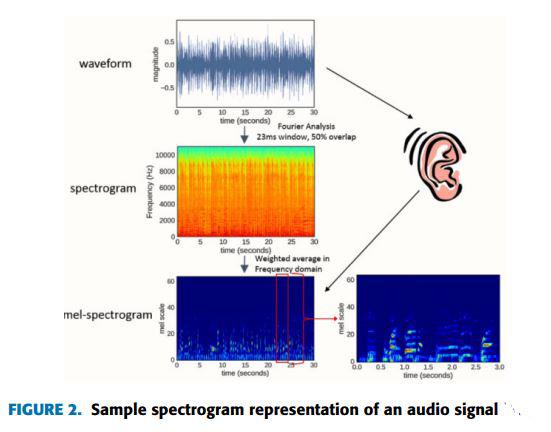
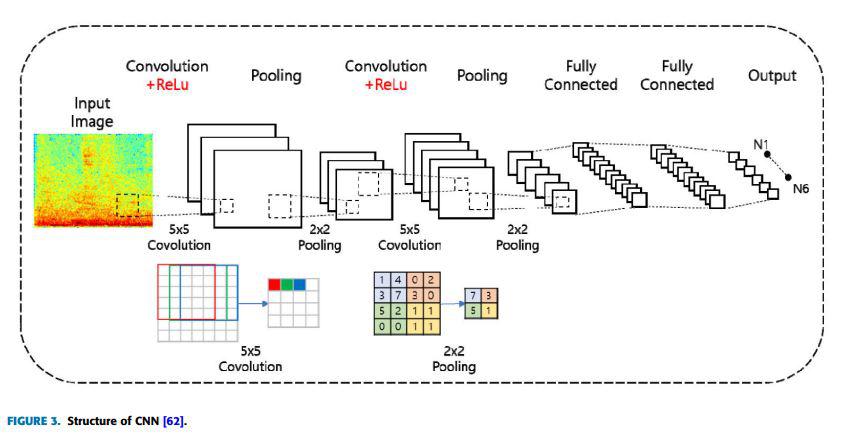
Les CNN sont couramment utilisés pour des tâches telles que la reconnaissance vocale, la classification de la musique et la séparation des sources audio. Les entrées des CNN peuvent être des signaux audios bruts en 1D ou leurs représentations en spectrogrammes 2D.
Points supplémentaires :
- Les CNN peuvent accepter des signaux audios bruts en 1D ou des spectrogrammes comme entrées.
- Un CNN typique comprend plusieurs couches de convolution, une unité linéaire rectifiée (ReLU), des couches de pooling, des couches entièrement connectées et une couche softmax.
- Les couches de convolution appliquent des filtres aux signaux d’entrée pour produire des cartes de caractéristiques.
- La fonction d’activation ReLU transforme les valeurs d’entrée négatives en zéro tout en conservant les valeurs positives, ajoutant de la non-linéarité et réduisant le risque de surapprentissage.
- Les couches de pooling diminuent les dimensions des cartes de caractéristiques d’entrée, permettant au modèle de se concentrer sur les éléments importants. Les méthodes de pooling courantes incluent le max pooling et l’average pooling.
- Les couches entièrement connectées relient chaque neurone d’une couche à la suivante et se situent généralement après les couches de convolution.
- La couche softmax convertit la sortie du CNN en une distribution de probabilités, ce qui est utile pour les tâches de classification multi-classes, car elle attribue une étiquette de classe en fonction des probabilités qui totalisent un.
4. Méthodes d'apprentissage profond utilisant des CNN
Cette section examine plusieurs études sur la classification sonore à l’aide de divers modèles d’apprentissage profond, en particulier les réseaux de neurones convolutionnels (CNN).
Voici les principales conclusions :
- Shin et Choi ont exploré différentes architectures de CNN (comme ResNet, DenseNet, VGG16, etc) pour classifier le bruit entre les étages, atteignant des précisions allant jusqu’à 99,5 %.
- Khamparia et Park Lee ont utilisé des CNN avec des spectrogrammes pour classer le bruit environnemental, avec des précisions variantes entre 77 et 99,25 %.
- Al-Hattab, Mushtaq et Lesnichaia ont étudié la classification des sons et de la parole à l’aide de divers modèles de CNN et de techniques d’augmentation de données, obtenant des précisions élevées (jusqu’à 99,49 %).
Il existe également différentes techniques d’apprentissage profond, notamment les CNN, pour la classification sonore. Voici un résumé des points clés :
- Spectrogrammes et CNN : De nombreuses recherches utilisent des représentations spectrogrammes des signaux audio (comme les spectrogrammes log-Mel, les coefficients cepstraux en échelle Mel (MFCC) et la transformation de Fourier à court terme (STFT)) comme entrées pour les modèles de CNN, dans des tâches telles que la classification du bruit environnemental, des genres musicaux et des accents.
- Performance des modèles : Les architectures de CNN comme ResNet, DenseNet, VGG16 et EfficientNet sont couramment utilisées. Beaucoup de ces modèles, y compris VGG16 et ResNet, atteignent une précision de classification élevée sur divers ensembles de données tels qu’UrbanSound8K, ESC-10 et GTZAN, souvent supérieure à 90 %.
- Augmentation de données : Plusieurs méthodes appliquent des techniques d’augmentation de données, comme l’étirement temporel, le décalage de hauteur et la compression de plage dynamique, pour pallier le manque de données et améliorer la capacité de généralisation des modèles.
5. Conclusion
En définitive, La classification audio basée sur l’intelligence artificielle et l’apprentissage profond s’impose aujourd’hui comme un domaine incontournable, transformant à la fois notre quotidien et nos interactions avec les technologies. L’évolution, des approches traditionnelles telles que les SVM, KNN et HMM, vers des modèles plus puissants comme les CNN, RNN, autoencodeurs et Transformers, illustre les progrès remarquables réalisés dans la capacité des machines à analyser et comprendre les signaux sonores.
Les points essentiels à retenir sont les suivants :
* La classification audio joue un rôle majeur dans des applications variées : reconnaissance vocale, assistants numériques, sécurité, santé et divertissement.
* Les techniques d’apprentissage profond surpassent les approches classiques grâce à leur aptitude à détecter automatiquement des motifs complexes dans de vastes ensembles de données.
*Les modèles modernes offrent une précision et une flexibilité élevées, mais exigent en contrepartie des ressources importantes en données et en puissance de calcul.
Au-delà des avancées actuelles, de nouvelles perspectives s’ouvrent : l’intégration de modèles plus légers et économes en énergie pour les dispositifs embarqués, l’amélioration de la robustesse face aux environnements sonores bruyants, ou encore l’exploration de systèmes multimodaux combinant audio, image et texte pour une compréhension plus globale.
6. Illustration Vidéo
En cours de Réalisation
7. Voir aussi...
Lien vers mon speechChoudja Ngami Harold
Stagiaire a l'irex
No comments yet. Start a new discussion.