IREX - Du scoring en Intelligence Artificielle
Dans un monde où de nouvelles IA émergent chaque Lundi, le scoring offre un cadre clair et objectif pour comparer, évaluer et transformer la confusion en décisions éclairées.
- Introduction
- Le concept de scoring en IA
- Méthodologie de calcul du score
- Cas pratique : TabbyML et ses alternatives
- Présentation des différentes solutions
- Tableau comparatif détaillé
- Critères et pondération pour le scoring
- Évaluation et scoring des modèles
- Résultats et recommandations finales
- Conclusion
1. Introduction
Dans l'écosystème en perpétuelle évolution de l'Intelligence Artificielle, de nouvelles solutions émergent chaque Lundi, créant un défi majeur pour les décideurs techniques : comment choisir la meilleure solution parmi une multitude d'options ? Qu'il s'agisse d'assistants de code, de modèles de langage ou d'outils de productivité, la prolifération des alternatives rend la prise de décision de plus en plus complexe.
Pour répondre à ce défi, cet article présente une méthodologie rigoureuse basée sur le scoring quantitatif. Cette approche transforme un processus de sélection subjectif en une évaluation objective, mesurable et reproductible. Nous définirons des critères précis comme la taille de la communauté, la fréquence des mises à jour, la qualité de la documentation et la facilité d'intégration, puis nous leur attribuerons des poids relatifs pour calculer un score global.
Cette méthodologie sera illustrée à travers l'étude comparative des solutions open source de complétion de code alternatives à TabbyML, démontrant comment le scoring permet de naviguer avec discernement dans l'univers complexe des outils d'IA et de faire des choix technologiques éclairés.
2. Le concept de scoring en IA
Le scoring en Intelligence Artificielle est une approche méthodique qui permet d'évaluer et de comparer différents modèles ou solutions en se basant sur des critères objectifs et mesurables. Cette méthode remplace l'intuition par la quantification, offrant une base solide pour la prise de décision.
Plutôt que de se fier aux tendances du marché ou aux opinions subjectives, le scoring fournit une mesure quantitative qui aide à prendre des décisions éclairées. Chaque modèle reçoit un score global qui synthétise sa performance technique, sa maturité communautaire et sa pertinence pour un contexte spécifique.
L'intérêt du scoring est multiple : il offre une vision claire et hiérarchisée des solutions disponibles, permet de justifier objectivement le choix d'une solution auprès des équipes techniques et des parties prenantes, et facilite la réévaluation périodique des choix technologiques. Cette approche est universellement applicable à toute solution IA, des assistants de code aux modèles de vision par ordinateur.
3. Méthodologie de calcul du score
Pour comparer objectivement différents modèles d'IA, nous utilisons une formule mathématique qui combine tous les critères sélectionnés en un score global unique. Cette approche garantit la reproductibilité et la transparence de l'évaluation.
Dans cette formule, chaque critère est préalablement normalisé par rapport à la valeur maximale observée parmi tous les modèles évalués. Cette normalisation garantit que tous les critères contribuent équitablement au score final, indépendamment de leur unité de mesure ou de leur ordre de grandeur.
Le score final est compris entre 0 et 1, où 1 représente la performance maximale théorique. Un score proche de 1 indique que le modèle excelle sur l'ensemble des critères retenus, tandis qu'un score faible révèle des limitations significatives. Cette approche permet un classement objectif et facilite la communication des résultats aux différentes parties prenantes.
4. Cas pratique : TabbyML et ses alternatives
Après avoir présenté le concept général du scoring et la méthodologie de calcul, il est pertinent d’illustrer cette approche par un cas concret. Nous avons choisi TabbyML, une solution open source de génération de code basée sur l’IA, afin de montrer comment le scoring peut aider à comparer différents outils.
L’idée est de mesurer TabbyML face à plusieurs alternatives similaires en prenant en compte des critères objectifs tels que : le nombre d’utilisateurs actifs, le nombre de forks GitHub, le volume de contributions récentes, ou encore la rapidité de mise à jour. Grâce à la formule de scoring, chaque critère est pondéré puis combiné dans un score global qui permet de classer les solutions.
Cette étude de cas démontre concrètement comment un processus de scoring peut faciliter la prise de décision, en transformant des données brutes en un indicateur simple et lisible, utile pour choisir la solution la plus adaptée aux besoins réels d’une équipe ou d’une organisation.
a. Pourquoi explorer des alternatives à TabbyML
TabbyML, bien qu'étant une solution performante, présente certaines limitations qui justifient l'exploration d'alternatives open source. L'écosystème diversifié des solutions de complétion de code offre des opportunités d'optimisation selon les contraintes spécifiques de chaque projet.
Compatibilité matérielle
Certaines solutions sont optimisées pour fonctionner efficacement sur CPU, éliminant la dépendance aux GPU coûteux et permettant un déploiement plus flexible.
Facilité de déploiement
Des alternatives proposent des méthodes de déploiement simplifiées via Docker ou des scripts automatisés, réduisant considérablement le temps de mise en production.
Licence et personnalisation
L'open source offre une liberté totale de personnalisation, modification du code source et adaptation aux besoins spécifiques de l'entreprise.
Performance spécialisée
Certains modèles sont spécifiquement optimisés pour des langages particuliers ou des domaines d'application, offrant de meilleures performances dans ces contextes.
b. Fonctionnalités clés des solutions alternatives
Les solutions alternatives à TabbyML se distinguent par un ensemble de fonctionnalités qui répondent aux besoins variés des équipes de développement. Ces caractéristiques techniques et fonctionnelles constituent les piliers de leur adoption en entreprise.
- Auto-hébergement sécurisé : Déploiement complet sur infrastructure locale, garantissant la confidentialité du code et la conformité aux politiques de sécurité entreprise.
- Compatibilité multi-langages : Support natif des langages populaires (Python, JavaScript, TypeScript, Go, Rust, C++, Java) avec optimisations spécifiques par langage.
- Optimisation CPU : Fonctionnement efficace sur processeurs standards sans nécessiter de GPU dédié, réduisant les coûts d'infrastructure.
- Intégration IDE native : Extensions dédiées pour VS Code, Neovim, JetBrains et autres environnements, avec API RESTful pour intégrations personnalisées.
- Communauté active : Écosystème open source dynamique avec contributions régulières, corrections rapides et évolutions continues basées sur les retours utilisateurs.
- Performance optimisée : Algorithmes d'inférence optimisés, cache intelligent et traitement en temps réel pour une expérience utilisateur fluide.
5. Présentation des différentes solutions
Voici un panorama détaillé des principales alternatives open source à TabbyML, chacune apportant ses spécificités techniques et ses avantages concurrentiels.
CodeGeeX
Modèle multi-langages de nouvelle génération, spécialement optimisé pour l'exécution CPU. CodeGeeX se distingue par sa facilité de déploiement via Docker et sa communauté active qui contribue régulièrement à son amélioration.
Lien du projet : https://github.com/THUDM/CodeGeeX
WizardCoder
Dérivé de StarCoder et optimisé spécifiquement pour la complétion de code, WizardCoder offre un excellent compromis entre performance et facilité d'utilisation. Auto-hébergeable via Docker ou scripts personnalisés.
Lien du projet : https://github.com/nlpxucan/WizardLM/tree/main/WizardCoder
CodeT5
Modèle basé sur l'architecture T5, particulièrement adapté aux projets collaboratifs. CodeT5 excelle dans la compréhension contextuelle et supporte efficacement l'usage CPU pour les déploiements contraints.
Lien du projet : https://github.com/salesforce/CodeT5
StarCoder
Projet phare de l'initiative BigCode, StarCoder représente l'état de l'art en matière de complétion de code open source. Multi-langages, performant et entièrement auto-hébergeable.
Lien du projet : https://github.com/bigcode-project/starcoder
Aider
Assistant pour l'édition et la complétion de code en contexte. Aider se distingue par sa capacité à comprendre et modifier des projets entiers, déployable entièrement en local.
Lien du projet : https://github.com/paul-gauthier/aider
Continue
Alternative directe à GitHub Copilot, Continue s'intègre nativement avec VS Code et JetBrains. Auto-hébergeable via serveur local, il offre une expérience utilisateur similaire aux solutions propriétaires.
Lien du projet : https://github.com/continuedev/continue
CodeGenius
Assistant open source combinant génération et complétion de code. Solution émergente avec un potentiel intéressant, déployable via Docker pour une mise en place rapide.
Lien du projet : https://github.com/craftingeagle/CodeGenius
FireCoder
Assistant IA conçu spécifiquement pour optimiser l'expérience de développement local. FireCoder mise sur la simplicité et l'efficacité.
Lien du projet : https://github.com/FireCoderAI/firecoder
6. Tableau comparatif détaillé
Ce tableau présente une analyse comparative exhaustive de toutes les solutions évaluées, incluant TabbyML comme référence. Les données sont collectées à partir des repositories GitHub officiels et reflètent l'état actuel de chaque projet.
| Solution | Déploiement CPU | Langages supportés | Auto-hébergeable | Type | Facilité de déploiement | Commentaires | Licence | Taille CM | Forks | Followers | MR dernière année |
|---|---|---|---|---|---|---|---|---|---|---|---|
| TabbyML | Partiel (préférable GPU) | Multi-langages | Oui | Assistant IA | Moyen | Très performant, nécessite GPU | Apache 2.0 | 32k | 1.6k | 141 | 910 |
| CodeGeeX | Oui | Multi-langages | Oui | Modèle IA | Docker facile | Communauté active | Apache 2.0 | 8.6k | 662 | 91 | 21 |
| WizardLM | Oui | Multi-langages | Oui | Modèle IA | Docker / Script | Optimisé code | Apache 2.0 | 9.5k | 735 | 109 | 12 |
| WizardCoder | Oui | Multi-langages | Oui | Modèle IA | Docker / Script | Optimisé code | Apache 2.0 | 9.5k | 735 | 109 | 12 |
| CodeT5 | Oui | Multi-langages | Oui | Modèle IA | Docker / Script | Collaboratif | BSD-3-Clause | 3.1k | 479 | 45 | 5 |
| StarCoder | Oui | Multi-langages | Oui | Modèle IA | Docker / Script | BigCode performant | Apache 2.0 | 7.4k | 528 | 71 | 7 |
| Aider | Oui | Multi-langages | Oui | Assistant IA | Script / Docker | Édition contextuelle | Apache 2.0 | 37k | 3.4k | 216 | 179 |
| Continue | Oui | Multi-langages | Oui | Extension + serveur | Facile (IDE intégré) | Alternative Copilot | Apache 2.0 | 28.6k | 3.4k | 124 | 2.246k |
| CodeGenius | Oui | Multi-langages | Oui | Assistant IA | Docker | Génération & complétion | MIT | 2 | 0 | 1 | 0 |
| FireCoder | Oui | Multi-langages | Oui | Assistant IA | Docker | Expérience locale | MIT | 42 | 2 | 2 | 28 |
7. Critères et pondération pour le scoring
Le choix des critères et de leur pondération constitue le cœur de notre méthodologie. Chaque critère a été sélectionné pour sa pertinence dans l'évaluation d'une solution d'IA open source et sa capacité à prédire le succès d'une adoption en contexte professionnel.
| Critère | Poids | Justification | Valeur |
|---|---|---|---|
| Déploiement CPU | 0.10 | Important pour permettre l’exécution sur des machines sans GPU. Un poids modéré reflète le fait que l’IA peut bénéficier de GPU mais doit rester accessible. | Oui = 1, Partiel = 0.5 |
| Langages | 0.05 | Support multi-langages favorise l’adoption universelle. Poids faible car la plupart des solutions modernes supportent plusieurs langages. | Multi-langages = 1, Autre = 0.5 |
| Auto-hébergeable | 0.05 | Flexibilité et contrôle sur l’infrastructure. Poids modéré car certaines solutions cloud peuvent compenser cette limitation. | Oui = 1, Non = 0 |
| Type | 0.05 | Différencie Assistant IA, Modèle IA ou Extension. Poids faible car cela impacte moins la performance globale que la communauté ou l’activité récente. | Assistant IA = 1, Modèle IA = 0.9, Extension = 0.8 |
| Facilité | 0.10 | Facilité de déploiement impacte directement l’adoption. Poids moyen reflète l’importance de l’expérience utilisateur. | Facile (IDE intégré)=1, Docker facile=0.9, Docker/Script=0.8, Script/Docker=0.7, Moyen=0.5, Docker=0.6 |
| Commentaires | 0.10 | Qualité des fonctionnalités, optimisation et pertinence pour les développeurs. Poids moyen pour valoriser les solutions bien documentées et actives. | Présence de mots-clés = 1, sinon 0.5 |
| Licence | 0.05 | Licence open-source favorise contribution et adoption. Poids faible car la majorité sont Apache ou MIT, mais reste un critère légal important. | Apache/MIT = 1, Autres = 0.5 |
| Taille CM | 0.05 | Solutions légères sont plus faciles à déployer et moins gourmandes en ressources. Poids faible car ce critère est relatif et souvent compensé par GPU/CPU. | Normalisé par rapport à la plus grande taille |
| Forks | 0.15 | Indicateur de la popularité et de l’engagement communautaire. Poids élevé car plus la communauté est active, meilleure la maintenance et support. | Nombre réel de forks normalisé |
| Followers | 0.10 | Indique la visibilité et la confiance dans le projet. Poids moyen car c’est complémentaire aux forks et MR. | Nombre réel de followers normalisé |
| MR dernière année | 0.20 | Mesure l’activité récente et la maintenance. Poids élevé car un projet actif est critique pour fiabilité et évolution. | Nombre de MR normalisé |
8. Évaluation et scoring des modèles
L'application de notre méthodologie de scoring révèle des différences significatives entre les solutions évaluées. Cette analyse quantitative met en lumière les forces et faiblesses de chaque alternative par rapport à TabbyML.
Chaque solution est évaluée selon nos 11 critères pondérés. Les données sont normalisées pour garantir une comparaison équitable, puis agrégées selon notre formule de scoring pour produire un score final compris entre 0 et 1.
Le scoring révèle que l'activité récente (merge requests) et la taille de la communauté (forks) sont les facteurs les plus discriminants. Ces critères reflètent la vitalité d'un projet open source et sa capacité à évoluer face aux besoins des utilisateurs.
Fonction de scoring et métrique d'évaluation
Visualisation de la fonction de scoring appliquée aux différents critères d'évaluation
9. Résultats et recommandations finales
Classement final des solutions
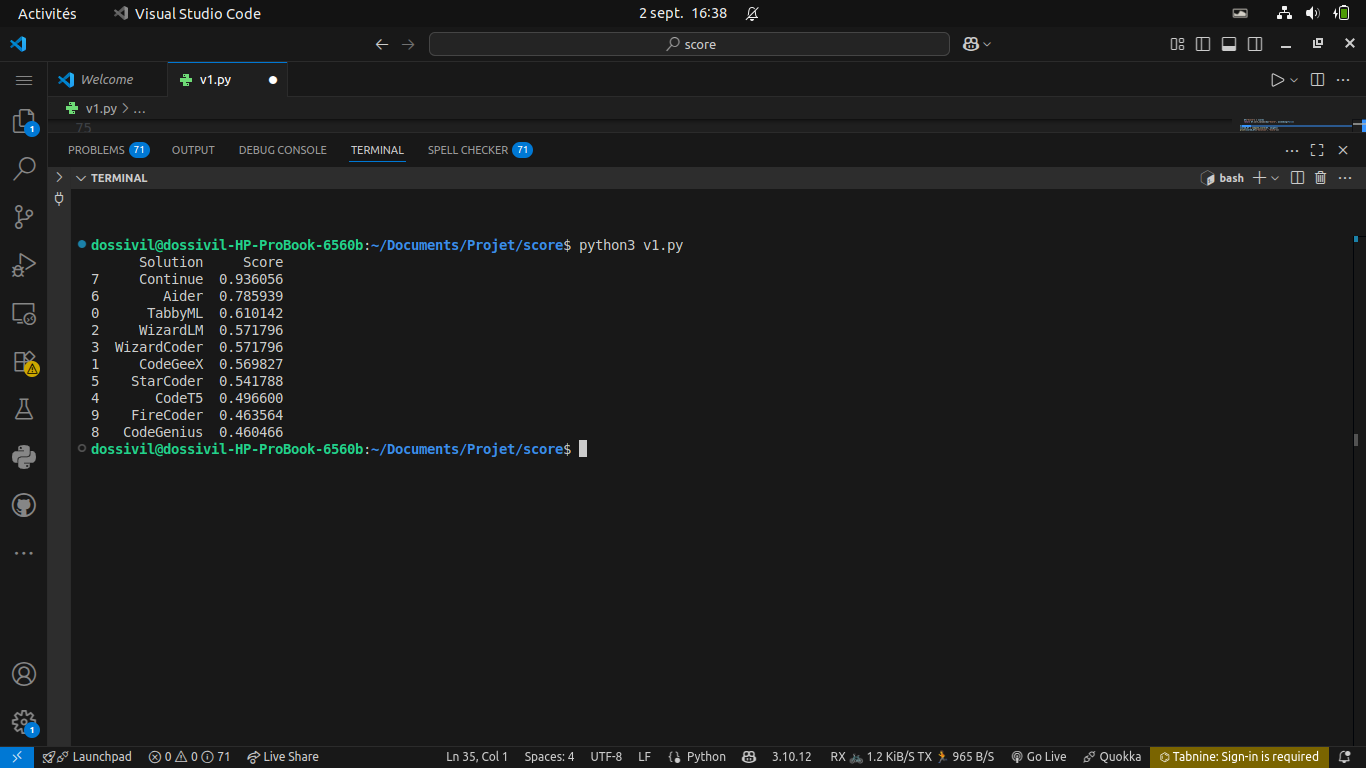
Scores finaux obtenus par chaque solution selon notre méthodologie
Continue obtient le score le plus élevé avec 0.936/1, confirmant son statut de meilleure alternative à TabbyML selon notre analyse.
10. Conclusion
Cette étude démontre l'efficacité du scoring quantitatif pour naviguer dans l'écosystème complexe des solutions d'IA. La méthodologie présentée est reproductible et adaptable à tout domaine technologique, offrant aux décideurs un outil objectif pour des choix éclairés.
L'émergence de Continue comme leader confirme l'importance de l'activité communautaire et de la facilité d'adoption
No comments yet. Start a new discussion.