IREX - La Classification des Audio basée sur la Technique des CNN(Convolutional Neural Networks)
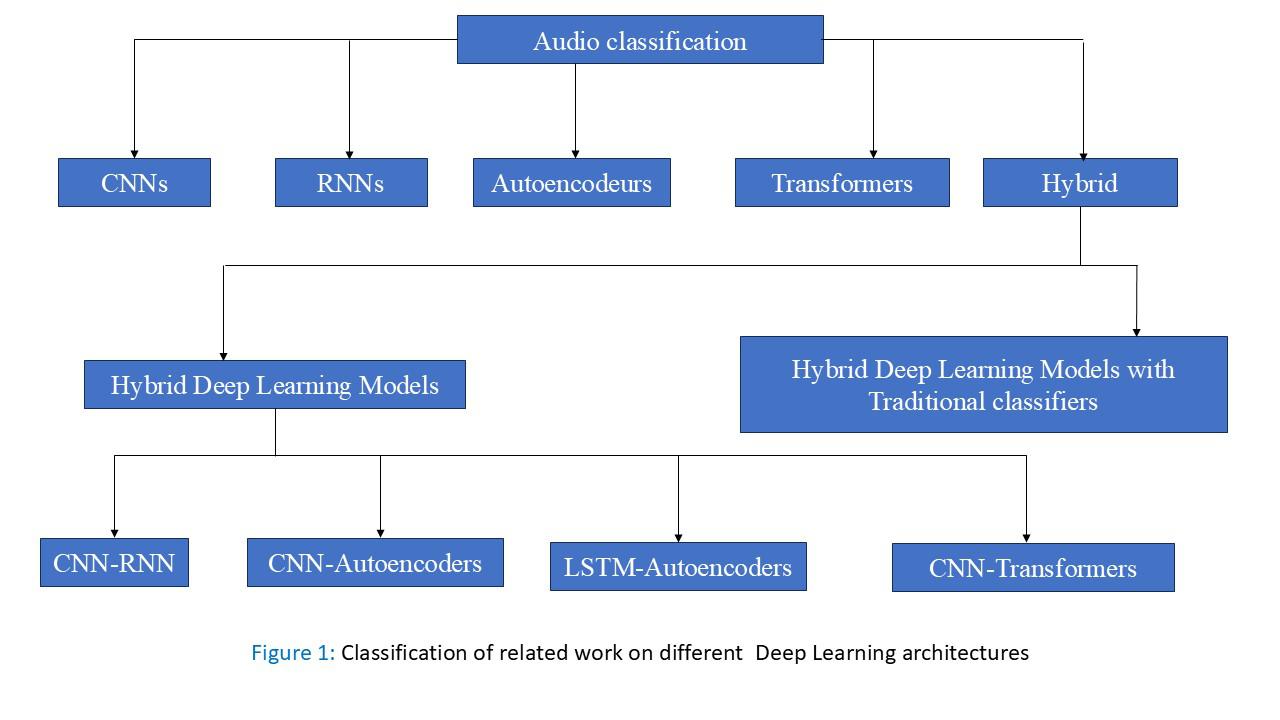
Depuis la fin des années 90, l’apprentissage profond, avec les CNN, RNN et autoencodeurs, révolutionne la reconnaissance vocale, musicale et la détection sonore.
- 1952 : Bell Labs développe Audrey, premier système de reconnaissance vocale.
- Années 1960–1970 : généralisation des HMM et des MFCC.
- Années 1980 : usage des méthodes classiques (KNN, SVM).
- 1989 : Yann LeCun introduit les CNN.
- 1990: apparition de bases de données comme TIMIT.
- 1998: premiers usages des CNN pour la reconnaissance vocale.
- Années 2000: intégration des RNN pour capturer la dépendance temporelle.
- À partir de 2010: essor du deep learning grâce aux GPU.
- 2014: popularité des LSTM et des autoencodeurs.
- 2017: révolution des Transformers pour le traitement séquentiel.
- Depuis 2020 : modèles hybrides (CNN, RNN, Transformers) offrant des performances inégalées.
1. Introduction
La classification audio améliore la reconnaissance vocale, le contrôle sans contact et des applications comme les assistants vocaux, la domotique ou la sécurité. Elle distingue parole, musique et sons environnementaux. Les méthodes classiques (SVM, KNN, HMM) ont été supplantées par l’apprentissage profond(CNN, RNN, autoencodeurs, transformers), plus précis mais exigeant en données et en calcul. En transformant les signaux en spectrogrammes ou MFCC, ces modèles facilitent la reconnaissance vocale, l’identification des locuteurs et la segmentation audio.
2. Historique
a. Période des approches traditionnelles (1950 – 2000)
b. Période du deep learning et des modèles avancés (2000 – aujourd’hui)
3. Architecture des CNN
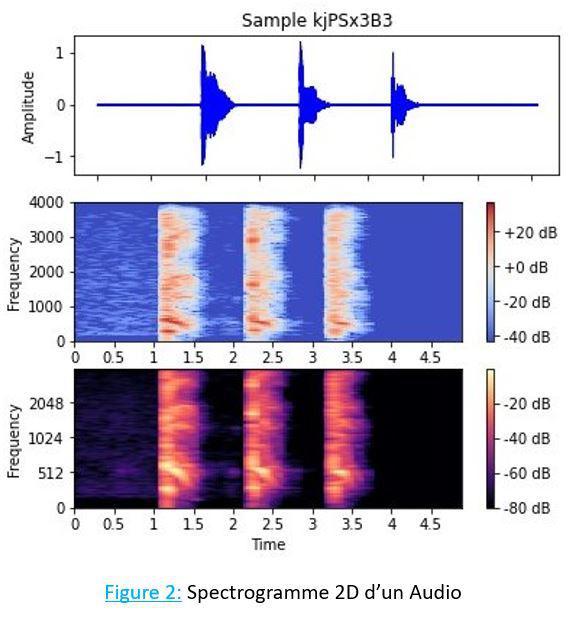
a. Représentation des signaux audio pour les CNN
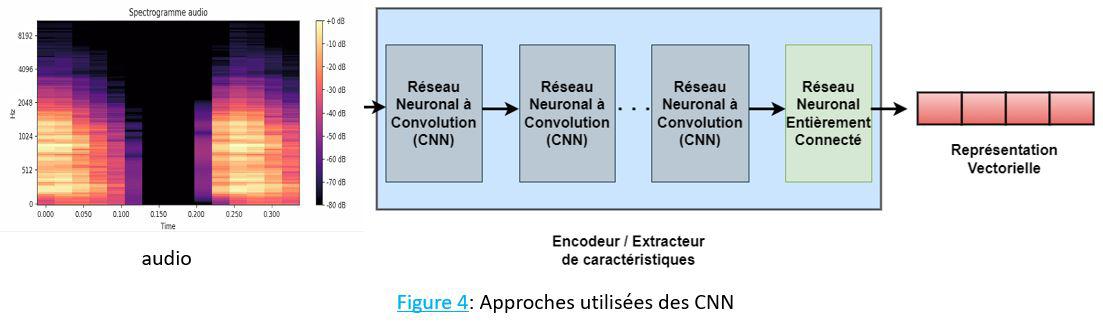
Les CNN sont couramment utilisés pour des tâches telles que la reconnaissance vocale, la classification de la musique et la séparation des sources audio. Les entrées des CNN peuvent être des signaux audios bruts en 1D ou leurs représentations en spectrogrammes 2D.
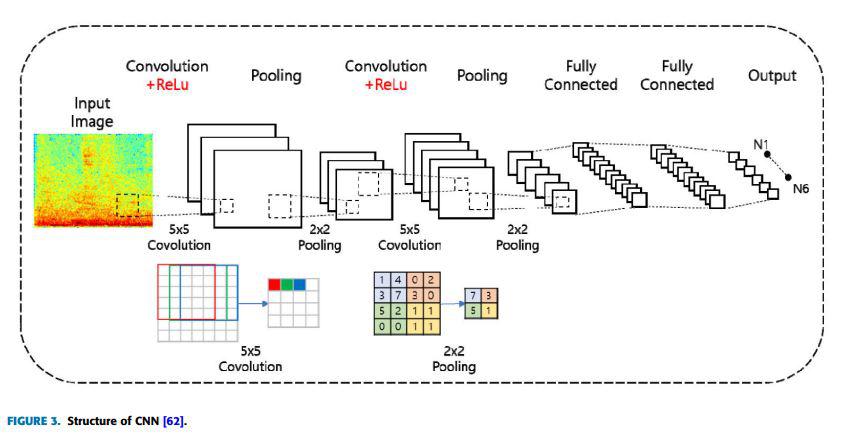
b. Structure typique d’un CNN
Un CNN typique comprend plusieurs couches de convolution, une unité linéaire rectifiée (ReLU), des couches de pooling, des couches entièrement connectées et une couche softmax.
- Les couches de convolution appliquent des filtres aux signaux d’entrée pour produire des cartes de caractéristiques.
- La fonction d’activation ReLU transforme les valeurs d’entrée négatives en zéro tout en conservant les valeurs positives, ajoutant de la non-linéarité et réduisant le risque de surapprentissage.
- Les couches de pooling diminuent les dimensions des cartes de caractéristiques d’entrée, permettant au modèle de se concentrer sur les éléments importants. Les méthodes de pooling courantes incluent le max pooling et l’average pooling.
- Les couches entièrement connectées relient chaque neurone d’une couche à la suivante et se situent généralement après les couches de convolution.
- La couche softmax convertit la sortie du CNN en une distribution de probabilités, ce qui est utile pour les tâches de classification multi-classes, car elle attribue une étiquette de classe en fonction des probabilités qui totalisent un.
4. Méthodes d'apprentissage profond utilisant des CNN
a. Études existantes sur les CNN
Cette section examine plusieurs études sur la classification sonore à l’aide de divers modèles d’apprentissage profond, en particulier les réseaux de neurones convolutionnels (CNN).
Voici les principales conclusions :
- Shin et Choi ont exploré différentes architectures de CNN (comme ResNet, DenseNet, VGG16, etc) pour classifier le bruit entre les étages, atteignant des précisions allant jusqu’à 99,5 %.
- Khamparia et Park Lee ont utilisé des CNN avec des spectrogrammes pour classer le bruit environnemental, avec des précisions variantes entre 77 et 99,25 %.
- Al-Hattab, Mushtaq et Lesnichaia ont étudié la classification des sons et de la parole à l’aide de divers modèles de CNN et de techniques d’augmentation de données, obtenant des précisions élevées (jusqu’à 99,49 %).
b. Techniques et approches utilisées des CNN
Il existe également différentes techniques d’apprentissage profond, notamment les CNN, pour la classification sonore. Voici un résumé des points clés :
- Spectrogrammes et CNN : De nombreuses recherches utilisent des représentations spectrogrammes des signaux audio (comme les spectrogrammes log-Mel, les coefficients cepstraux en échelle Mel (MFCC) et la transformation de Fourier à court terme (STFT)) comme entrées pour les modèles de CNN, dans des tâches telles que la classification du bruit environnemental, des genres musicaux et des accents.
- Performance des modèles : Les architectures de CNN comme ResNet, DenseNet, VGG16 et EfficientNet sont couramment utilisées. Beaucoup de ces modèles, y compris VGG16 et ResNet, atteignent une précision de classification élevée sur divers ensembles de données tels qu’UrbanSound8K, ESC-10 et GTZAN, souvent supérieure à 90 %.
- Augmentation de données : Plusieurs méthodes appliquent des techniques d’augmentation de données, comme l’étirement temporel, le décalage de hauteur et la compression de plage dynamique, pour pallier le manque de données et améliorer la capacité de généralisation des modèles.
5. Conclusion
En définitive, La classification audio par apprentissage profond est devenue essentielle, avec des applications en reconnaissance vocale, sécurité, santé ou divertissement. Les modèles modernes (CNN, RNN, Transformers, etc.) surpassent les approches classiques grâce à leur capacité à détecter automatiquement des motifs complexes, mais demandent beaucoup de données et de calcul. L’avenir se tourne vers des modèles plus légers, robustes au bruit et capables d’intégrer plusieurs modalités (audio, image, texte).
6. Illustration Vidéo
Pour une meilleure compréhension, la vidéo suivante illustre le processus et les résultats de classification sonore.
7. Voir aussi...
Dans cette optique, vous pouvez consulter :
Choudja Ngami Harold
Stagiaire a l'irex
No comments yet. Start a new discussion.