IREX - Prêter sans se tromper: le pari de l'IA dans la finance
Venez, découvrons ensemble comment les algorithmes de machine learning permettent d'automatiser la prise des décisions de crédit au sein des banques
Sommaire
1. Introduction
Il est de notoriété commune que les opérations de crédit ont toujours été et resteront au cœur de l’activité de nos institutions financières, en particulier des banques commerciales. Cependant, deux questions centrales demeurent : jusqu’à quel point peut-on faire confiance à un client lambda qui souhaite recourir à un emprunt ? Et comment rentabiliser nos prêts ? L’objectif de cet article est d’introduire la notion de risque de crédit et d’examiner comment les algorithmes de machine learning permettent de s'assurer de la solvabilité du client.
2. Le défi quotidien des banques: prêter ou ne pas prêter
Considérons que vous ayez un ami, qui vous demande un peu d’argent en promettant vous rembourser le lendemain. En supposant que vous ayez de quoi satisfaire à ses attentes, il va également de soi que vous vous intéressez un tant soit peu à son historique : était-il par le passé fidèle dans ses précédents engagements ?
Il y a donc un risque à prêter son argent à cet ami : il s’agit du risque de perdre cet argent définitivement s’il est incapable de vous rembourser ensuite.
Si ce risque, se situe en dessous du seuil que vous pouvez tolérer, alors vous pouvez lui confier cet argent ; autrement il serait peut-être mieux de garder cet argent pour vous.
Si, à titre personnel, vous pouvez vous fier à vos sentiments, votre intuition ou votre amitié pour évaluer un risque, cette approche reste envisageable à petite échelle. Pour une banque, en revanche, qui traite parfois des milliers de demandes de crédit en un seul mois, il est impératif de se poser systématiquement les questions fondamentales évoquées précédemment :
- Jusqu’à quel point peut-on faire confiance à ce client lambda qui veut recourir à un emprunt ?
- Comment rentabiliser nos prêts ?
3. Quelques notions fondamentales
Avant de nous pencher sur la notion de risque de crédit, il est important que nous mentionnons préalablement que la notion de taux d’intérêt, joue un rôle central car le taux d’intérêt associé à un prêt est la variable qui permet de supporter l’inflation, la rémunération du prêteur, et également le risque de défaut qui représente le risque que l’emprunteur ne parvienne pas à recouvrer sa dette. Il vient donc que le risque de défaut d’un client rentre dans le calcul du taux d’intérêt du prêt qu’il peut se voir accordé.
Le risque de défaut constitue donc une composante très importante du risque de crédit.
Le risque de crédit donc, au sens large, englobe le risque de défaut, mais aussi les pertes associées une fois le défaut réalisé (combien la banque perd effectivement après recouvrement, garanties, etc.).
La loi des grands nombres quant à elle est une loi mathématique qui, pour simplifier, dit qu’avec un grand nombre d’essais effectuées, la probabilité expérimentale qu’un évènement se réalise se rapproche de sa probabilité théorique.
Pour illustrer dans notre contexte, supposons que chaque client ait une probabilité de défaut (PD) de 15 %. Si nous considérons un grand nombre de clients, par exemple 10 000, alors le nombre attendu de clients faisant défaut est : N = 10 000×0,15=1 500.
Cependant, ce nombre n’est pas exact pour cette population : certains clients peuvent ne pas faire défaut malgré une PD élevée, et d’autres peuvent faire défaut même avec une PD plus faible. La loi des grands nombres nous assure que, lorsque le nombre de clients est très grand, la proportion réelle de défauts tendra vers la moyenne des PD, c’est-à-dire environ 15 %, avec une certaine variabilité naturelle.
4. Les méthodes traditionnelles d’évaluation du crédit
Avant l’arrivée des techniques modernes, les banques s’appuyaient surtout sur des méthodes classiques et des critères fixes. Par exemple :
- Les 5C du crédit : Caractère (fiabilité du client), Capacité (revenus), Capital (patrimoine), Conditions (situation économique), Collatéraux (garanties).
- Les ratios financiers : par exemple comparer les dettes aux revenus pour voir si la personne peut raisonnablement rembourser.
- Les scores de crédit traditionnels : des systèmes de points construits à partir de règles simples.
Ces approches sont claires et faciles à appliquer, mais elles ont leurs limites : elles ne capturent pas toujours toute la complexité des situations et peuvent être rigides. C’est justement à ce niveau qu’on retrouve toute la pertinence des méthodes de machine learning.
5. Cas pratique: L'apport du machine learning dans la prise de décision
a. Définition du machine learning?
Avant de vous présenter ici quelques algorithmes de machine learning, dans l’évaluation du risque d’un emprunteur, il est nécessaire que nous donnions une vue globale de ce que c’est le machine learning.
D’apres Arthur Samuel, un des pionniers de l’intelligence artificielle (1959), le machine learning est le domaine d’étude de l’intelligence artificielle, qui se fonde sur des approches mathématiques et statistiques pour donner aux ordinateurs la capacité d’« apprendre » à partir de données, c'est-à-dire d'améliorer leurs performances à résoudre des tâches sans être explicitement programmés pour chacune.
Un modèle dans le contexte du machine learning est un fichier entraîné, créé par un algorithme d'apprentissage, qui peut prédire des résultats ou prendre des décisions à partir de nouvelles données en se basant sur les schémas qu'il a appris lors de son entraînement.
b. Évaluation simplifiée de la solvabilité des clients
L’un des critères les plus décisifs dans le processus de l’évaluation de la solvabilité d’un client est sa probabilité de défaut (la probabilité que le client ne rembourse pas totalement la dette contractée dans les délais prévus par le contrat d’endettement). Pour l’évaluer, les banquiers font notamment recours aux données personnelles, professionnelles et financières du client, afin d’estimer sa capacité à rembourser ses dettes dans le temps impartis.
Supposons pour simplifier que nous ne nous intéresserons qu’à l’âge et au revenu (Income en anglais) de nos clients pour prendre nos décisions. Supposons également que nous avons un ensemble de clients initialement bien classés : les uns étant jugés en capacité de rembourser leurs dettes à temps (les clients sûrs) ; et les autres non (les clients défaillants).
Etant donné un nouveau client qu’on voudrait également situer dans une de ces classes, nous pouvons nous appuyer sur :
i. L’algorithme des K-plus proches voisins
L’algorithme des K-plus proches voisins (K-nearest neighbors, en anglais) consiste à fixer au préalable un nombre de voisins arbitraire noté ici K. Si parmi ces K-plus proches voisins, il y en a plus qui sont classés comme étant dans la capacité de rembourser leurs dettes à temps, alors ce nouveau client en fait partie ; sinon nous pouvons l’ajouter dans l’autre catégorie. En d’autres termes pour cet algorithme : c’est la majorité qui l’emporte ! L’illustration ci-dessus permet de visualiser l’algorithme des K-plus proches voisins. Nous disposons d’un ensemble de clients : les clients défaillants en rouge et les clients sûrs en bleu. Nous voulons ensuite classer le client, représenté par le point vert, dans l’une de ces catégories. En considérant dans notre algorithmes 5 plus proches « voisins », nous nous rendons compte que 4 voisins sont des clients sûrs et puisque cela représente la majorité, notre client sera aussi considéré comme un client sûr.
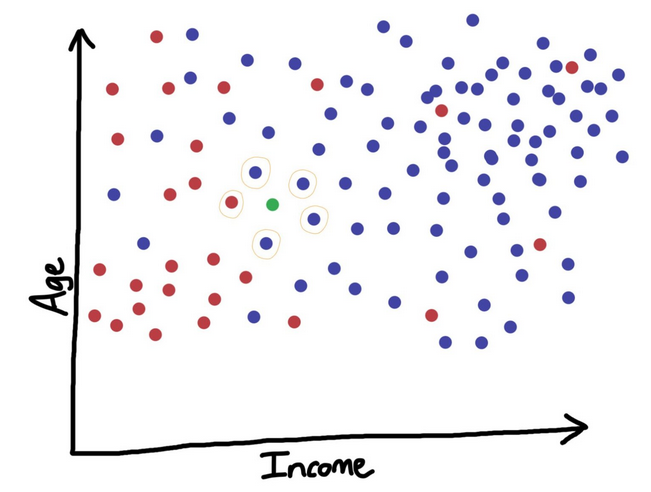
Le succès de cette méthode repose sur le choix du nombre K qui nous permet d’obtenir les résultats les plus précis c’est à dire de prendre la meilleure décision. Pour donc optimiser le choix de K, on teste le modèle pour différentes valeurs de K (que nous aurons à changer en amont) et l’on retiendra uniquement celle pour laquelle la précision du modèle est la plus grande. L’avantage majeur de l’algorithme des K-plus proches voisins est son extrême simplicité. Cependant, une des principales limites de cet algorithme est qu’il sous-performe sur un grand ensemble de données.
ii. La regression logistique
La régression logistique est un modèle de régression utilisé en classification binaire. Le but de cet algorithme est d’expliquer au mieux une variable binaire par des observations réelles nombreuses. L’hypothèse principale de cet algorithme est : la spécification logistique de la probabilité de défaut où, les variables explicatives représentent l’ensemble des caractéristiques quantitatives ou qualitatives observées sur un emprunteur, susceptibles d’influencer sa probabilité de défaut et les les paramètres à estimer (à l’aide des données sur les autres clients).
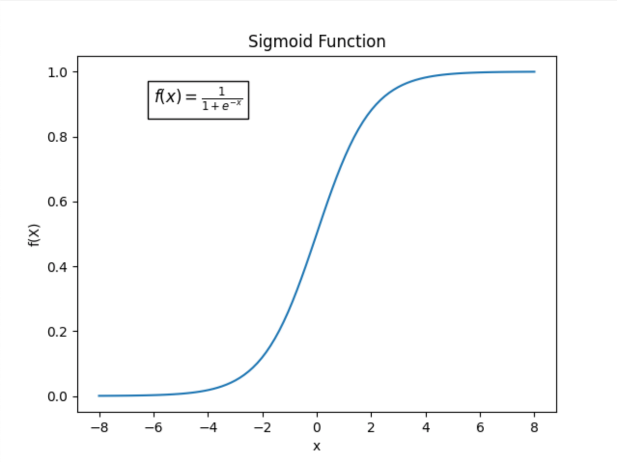
Le principe de cet algorithme, repose donc sur une fonction particulière, la fonction sigmoïde, définie par : Les principaux avantages à utiliser cette fonction sont :
- Elle renvoie toujours des valeurs entre 0 et 1, ce qui est une propriété caractéristique de toute fonction de probabilité.
- Parce qu’elle a une forme presque linéaire autour de 0 mais s’aplatie aux extrémités.
Cet algorithme renvoie donc directement la probabilité que le client soit un bon emprunteur (faible probabilité de défaut) ou pas (probabilité de défaut élevée). C’est donc à la banque de déterminer le seuil à partir duquel elle trouvera le client trop risqué ou pas et décidera soit de refuser la demande d’emprunt soit de modifier les conditions de l’emprunt (par exemple la réduction du montant à emprunter)
En guise d’illustration : Considérons un ensemble de clients dont nous avons les probabilités de défaut : En rouge les clients les plus défaillants, et en bleu les clients les plus sûrs. La fonction sigmoïde est donc déterminée à partir de ces ensembles de clients.
Pour simplifier cet exemple, ces probabilités ne seront calculées que sur la base du revenu (Income) des clients.
Etant donné un client nommé Ted, la banque voudrait savoir si ce dernier est un client défaillant ou un client sûr. Pour estimer ce que vaut sa probabilité de défaut, il nous suffit de déterminer ce que renvoie la fonction sigmoïde à partir du revenu de Ted qu’elle a reçu en entrée.

N.B : Le graphique ci-dessus représente la probabilité de NE PAS faire défaut !! Pour obtenir la probabilité de faire défaut il suffit retrancher cette quantité à 1 (i.e. 1-probabilité de NE PAS faire défaut)
En plus de sa simplicité, l’algorithme de régression logistique présente notamment l’avantage d’être le plus populaire pour estimer la probabilité de défaut, cependant un inconvénient majeur de la régression logistique est qu’elle repose sur l’hypothèse de la spécification logistique de la probabilité de défaut. Ce qui peut s’avérer trop rigide pour modéliser certains cas assez complexes.
6. Conclusion
L’évaluation de la solvabilité d’un emprunteur constitue l’un des enjeux majeurs de l’industrie financière. Tirer parti des avancées récentes en apprentissage automatique représente un atout considérable pour accroître la précision des prédictions. Au-delà des algorithmes classiques déjà évoqués, les analystes de crédit recourent de plus en plus à des méthodes sophistiquées, capables de mettre en évidence des relations non linéaires entre les variables. On peut citer notamment les forêts aléatoires (Random Forests), le gradient boosting, les machines à vecteurs de support (SVM), ainsi que les réseaux de neurones artificiels. Ces approches offrent une meilleure capacité de généralisation et permettent d’identifier des schémas complexes dans les données, améliorant ainsi la qualité des décisions de crédit.
7. Vidéo d'illustration
Dans la video suivante, nous donnerons plus de détail sur le fonctionnement des algorithmes des k-plus proches voisins et de regréssion logistique