IREX - Ragflow : Révolutionner la Recherche d’Informations avec le RAG
Ragflow est cet outils qui transforme l’accès à l’information en fusionnant récupération sémantique et génération intelligente pour livrer, en un clic, des réponses précises, contextualisées et prêtes
1. Introduction
Dans l’ère numérique actuelle, l’accès rapide et précis à l’information est crucial. Les entreprises et les chercheurs sont constamment à la recherche de moyens plus efficaces pour extraire des connaissances à partir de vastes ensembles de données. C’est ici qu’intervient Ragflow, un projet innovant visant à déployer la technologie RAG (Retrieval-Augmented Generation) pour transformer la manière dont nous interagissons avec l’information. En combinant la puissance de la récupération d’informations avec la génération de texte intelligente, Ragflow promet d’améliorer la qualité et la pertinence des réponses fournies aux utilisateurs, ouvrant la voie à des applications dans des domaines aussi variés que la recherche scientifique, l’aide à la décision ou encore l’assistance client.
2. Qu’est-ce que le RAG ?

Le RAG (Retrieval-Augmented Generation) est une approche hybride en intelligence artificielle qui combine deux composants principaux : un système de récupération d’informations et un modèle de génération de texte. Contrairement aux modèles de langage classiques qui génèrent des réponses uniquement basées sur leurs connaissances pré-entraînées, le RAG enrichit le processus en récupérant des informations pertinentes en temps réel à partir de bases de données ou de documents externes. Cela permet au modèle de produire des réponses plus à jour, plus précises et contextualisées, en s’appuyant sur des sources fiables.
3. Objectifs du Projet Ragflow
Le projet Ragflow a pour ambition de déployer une infrastructure scalable et accessible exploitant le RAG pour répondre aux besoins croissants en matière de recherche d’informations intelligentes. Les objectifs spécifiques incluent :
- Développer une plateforme ouverte permettant l’intégration facile de différentes sources de données (documents, bases de connaissances, API, etc.).
- Optimiser la performance du système RAG en réduisant le temps de réponse et en améliorant la pertinence des résultats.
- Assurer la confidentialité et la sécurité des données utilisées, en particulier dans des contextes sensibles comme la santé ou la finance.
- Faciliter l’adoption du RAG par des utilisateurs non techniques grâce à une interface intuitive et des outils de personnalisation.
4. Architecture Technique – Principe de fonctionnement
a. Architecture Technique
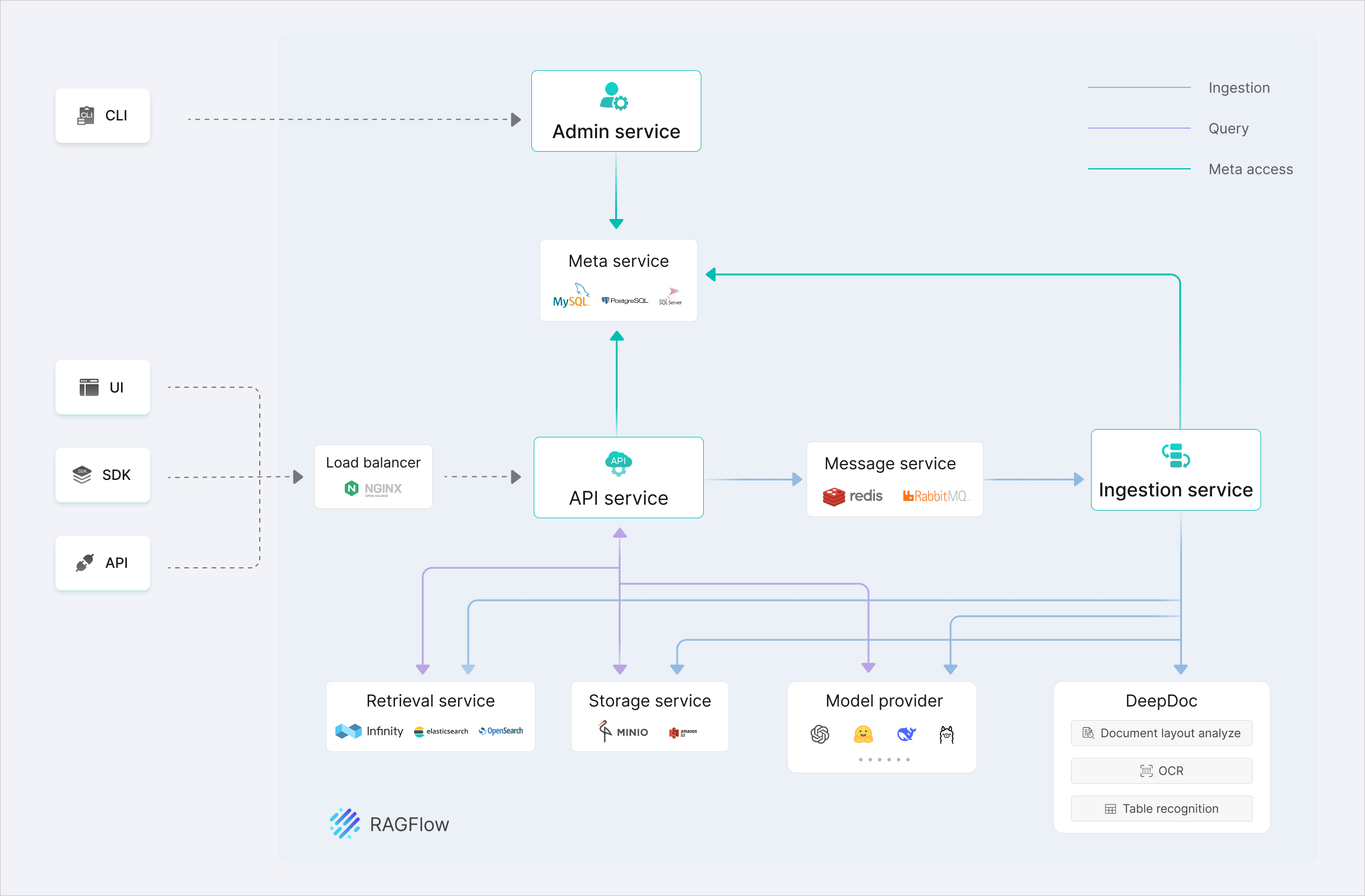
Ragflow fonctionne comme une chaîne entièrement orchestrée reliant l’ingestion des documents, leur traitement, l’indexation, la recherche et enfin la génération de réponses. L’ensemble des services collaborent pour offrir une architecture RAG robuste, scalable et automatisée.
- Admin Service : interface d’administration accessible via CLI, permettant de configurer la plateforme.
- Meta Service : cœur des métadonnées, s’appuyant sur MySQL, PostgreSQL ou SQL Server. Il centralise la configuration et l’état des projets.
- Load Balancer (Nginx) : point d’entrée de l’UI, des SDK et de l’API, répartissant la charge vers le service API.
- API Service : orchestrateur principal. Il traite les requêtes, interagit avec le stockage, la recherche, les modèles et DeepDoc.
- Message Service (Redis / RabbitMQ) : gère les communications asynchrones et les files de tâches pour l’ingestion documentaire.
- Ingestion Service : pipeline d’ingestion responsable du parsing, de l’OCR, de l’analyse de structure via DeepDoc et de la génération d’embeddings.
- Retrieval Service : moteur de recherche vectorielle basé sur Infinity, Elasticsearch ou OpenSearch.
- Storage Service (MinIO / OpenIO) : stockage des documents, artefacts et données extraites.
- Model Provider : connecteurs vers les modèles de génération et d’embeddings (OpenAI, LLaMA, DeepSeek, etc.).
- DeepDoc : module d’analyse avancée des documents (OCR, analyse de mise en page, reconnaissance de tables).
Cette architecture modulaire permet de faire monter en charge chaque composant indépendamment, tout en garantissant faible latence, haute disponibilité et traçabilité complète du flux RAG.
b. Principe de fonctionnement
Ragflow fonctionne comme une chaîne entièrement orchestrée reliant l’ingestion des documents, leur traitement, l’indexation, la recherche et enfin la génération de réponses. L’ensemble des services collaborent pour offrir une architecture RAG robuste, scalable et automatisée.
Tout commence lorsqu’un utilisateur ou un client externe (UI, SDK, API) interagit avec la plateforme. Les requêtes passent d’abord par le load balancer Nginx, qui distribue la charge vers le API Service. Celui-ci joue un rôle central : il reçoit les opérations de requête et d’ingestion(étapes nécessaires pour transformer un document brut en contenu exploitable par le moteur de recherche sémantique et le LLM) et communique avec l’ensemble des services internes.
Lors de l’ajout de nouveaux documents, l’API transmet les tâches d’ingestion au Message Service (Redis ou RabbitMQ), qui gère les files d’attente et déclenche le travail du Ingestion Service. Ce dernier analyse les documents grâce à DeepDoc (OCR, analyse de mise en page, extraction de tableaux), génère les embeddings et place les fichiers dans le Storage Service (MinIO, OpenIO), tandis que les métadonnées sont centralisées dans le Meta Service.
Une fois traités, les vecteurs sont indexés dans le Retrieval Service (Infinity, Elasticsearch ou OpenSearch), permettant une recherche sémantique rapide et efficace. Les modèles de génération et d'embeddings fournis par le Model Provider (OpenAI, LLaMA, DeepSeek, etc.) sont utilisés pour enrichir le contenu indexé et préparer les réponses.
Lorsqu’un utilisateur pose une question, l’API interroge d’abord le Retrieval Service pour récupérer les passages les plus pertinents. Ces informations sont ensuite combinées avec les modèles LLM du Model Provider afin de produire une réponse contextualisée. Le tout repose sur les métadonnées gérées par le Meta Service et peut être supervisé via le Admin Service.
Ainsi, Ragflow assure une boucle complète et automatisée : ingestion → analyse → stockage → indexation → recherche → génération, tout en garantissant une extensibilité, une modularité et une performance adaptées aux besoins professionnels.
5. Cas d’Usage et Applications
Ragflow peut être appliqué dans une multitude de domaines :
- Recherche scientifique : aider les chercheurs à extraire des informations pertinentes à partir de milliers de publications.
- Entreprises : offrir un assistant intelligent capable de répondre aux questions des employés en temps réel à partir de documents internes.
- Secteur public : améliorer l’accessibilité des services administratifs en fournissant des réponses précises aux citoyens.
- Éducation : créer des tuteurs intelligents capables de fournir des explications contextualisées à partir de manuels et de ressources pédagogiques.
6. Défis et Perspectives
Le déploiement de Ragflow n’est pas sans défis. Parmi les principaux obstacles figurent :
- La gestion de la qualité des données : les performances du RAG dépendent fortement de la qualité et de la fraîcheur des sources utilisées.
- La scalabilité : assurer une réponse rapide même avec des volumes massifs de données.
- L’interprétabilité : permettre aux utilisateurs de comprendre comment les réponses sont générées, pour renforcer la confiance.
- L’éthique et la neutralité : éviter les biais dans les réponses générées, en particulier dans des domaines sensibles.
À l’avenir, Ragflow pourrait évoluer vers une plateforme universelle de connaissance, intégrant des fonctionnalités de collaboration humain-IA, de personnalisation avancée et d’apprentissage continu à partir des interactions utilisateur.
7. Conclusion
Ragflow représente une avancée majeure dans le domaine de l’intelligence artificielle appliquée à la recherche d’informations. En exploitant le potentiel du RAG, il ouvre la voie à des systèmes plus intelligents, plus rapides et plus fiables, capables de transformer la manière dont nous accédons et utilisons la connaissance. À mesure que les données continuent de proliférer, des solutions comme Ragflow deviendront non seulement souhaitables, mais essentielles pour naviguer dans l’océan d’information du XXIe siècle.
No comments yet. Start a new discussion.