IREX - Le NLP, c’est quoi ? Comprendre comment l’IA traite le langage humain
Imaginez devoir discuter avec ChatGPT… uniquement en 1 et 0. '11000111 ? Pas très pratique. Et bien c'est pour nous éviter ce cauchemar que le NPL existe.
Sommaire
1. Introduction
Le langage est sans doute ce qui nous rend les plus humains. C’est aussi ce qui rend l’intelligence artificielle... compliquée. Comment permettre à une machine de comprendre nos mots, nos intentions, nos émotions ?
C’est tout l’objectif du Traitement Automatique du Langage Naturel — ou NLP pour Natural Language Processing. Cette discipline à l’intersection de la linguistique, de l’informatique et de l’intelligence artificielle vise à donner aux machines la capacité de lire, comprendre, générer et interagir en langage humain.
a- Aux origines du NLP
Les premières tentatives sérieuses remontent à 1954 avec le projet de traduction automatique Georgetown-IBM. La machine a alors traduit une soixantaine de phrases du russe vers l’anglais, impressionnant... mais purement scripté.
Dans les années 1960, le linguiste Noam Chomsky apporte un cadre théorique avec ses grammaires génératives, bien que celles-ci soient initialement trop rigides pour l’usage machine. Côté IA, on reste longtemps limité à des approches basées sur des règles manuelles.
b- Du symbolique au statistique, puis au profond
Evolution du NLP
1980–90
Montée des modèles statistiques : Hidden Markov Models (HMM), POS tagging, recherche d'information (IR).
2000
Émergence du machine learning supervisé (SVM, CRF) avec plus de données et de puissance de calcul.
2013
Naissance de Word2Vec (Google) : mots représentés sous forme de vecteurs de sens (embeddings).
2018
Arrivée des Transformers avec BERT : contextualisation du langage, révolution en NLP.
2020+
L'ère des LLMs : GPT-3, T5, BLOOM, LLaMA... Modèles capables de générer du texte à très grande échelle.
2. Pourquoi le langage humain est si complexe pour une machine
Pour un humain, comprendre une phrase semble naturel. Pourtant, derrière cette aisance se cache une complexité redoutable que les machines peinent à maîtriser. Le langage humain est ambigu, contextuel, évolutif, implicite... et souvent rempli de non-dits. En bref, c’est un vrai casse-tête algorithmique.
a. Ambiguïté lexicale et syntaxique
Les mots peuvent avoir plusieurs sens, et une même phrase peut s'interpréter de différentes manières selon la ponctuation ou le contexte.
b. Dépendance au contexte
Un mot ou une phrase n’a de sens que dans un contexte donné. Ce qui est évident pour nous ne l’est pas pour une machine.
c. Implicites et sous-entendus
Le langage humain est souvent implicite : nous devinons des choses sans qu’elles soient dites. Mais pour une machine, ce qui n’est pas explicite… n’existe pas.
d. Variabilité linguistique
Il existe mille façons de dire la même chose : tournures, synonymes, dialectes, fautes de frappe, expressions idiomatiques… tout cela complexifie l’analyse.
Comme on vient de le voir, comprendre le langage humain n'est pas une mince affaire pour une machine. Pourtant, les chercheurs n'ont cessé d'innover depuis plus de 70 ans pour franchir les obstacles du langage. Mais alors, comment le NLP se debrouille t'il pour transformer le langage naturel ? Quelles sont les grandes étapes qui permettent aux machines de devenir (un peu) plus linguistes ?
3. Les grandes étapes du NLP
3.1. Tokenisation
Avant de comprendre un texte, il faut d’abord le découper. En NLP, cette étape s'appelle la tokenisation. Elle consiste à fragmenter une phrase en unités de base appelées tokens : mots, ponctuation, ou parfois même sous-mots.
Exemple 1 — une phrase simple en français
Phrase : « Je t’aime beaucoup. »
Tokens attendus : ["Je", "t", "’", "aime", "beaucoup", "."]
Problème : la contraction « t’aime » doit être correctement séparée, ce qui n’est pas toujours bien géré par un tokenizer naïf.
3.2. Lemmatisation et Prétraitement
Une fois les tokens extraits, le NLP applique une série de traitements pour simplifier, normaliser ou purifier le texte. Ces étapes varient selon les objectifs, mais certaines sont incontournables :
a. Lemmatisation
La lemmatisation consiste à ramener chaque mot à sa forme canonique (ou lemme). Contrairement au stemming, elle respecte la grammaire et le sens du mot.
b. Stemming
Le stemming est une version plus brute du nettoyage. Il coupe les mots pour obtenir une racine, quitte à perdre du sens.
c. Suppression des stopwords
Les stopwords sont des mots très fréquents mais peu informatifs : « le », « de », « et », « alors », etc. On les supprime souvent pour se concentrer sur les mots clés.
3.3. Vectorisation
Les modèles d’IA ne peuvent travailler qu’avec des nombres. Il est donc nécessaire de convertir les mots en représentations numériques appelées vecteurs. C’est ce qu’on appelle la vectorisation ou l’embedding.
Il existe plusieurs méthodes de vectorisation, chacune avec ses avantages et ses limites :
a. Bag of Words (BoW)
La méthode la plus simple pour représenter un texte est de compter la fréquence des mots qu’il contient, sans se soucier de leur ordre. C’est ce qu’on appelle le Bag of Words, ou « sac de mots » en français. Imaginez que vous mettez tous les mots d’un texte dans un sac et que vous les comptez un par un.
Comment ça marche ?
- On construit un vocabulaire avec tous les mots uniques de l’ensemble des documents.
- Chaque document est alors représenté par un vecteur indiquant la fréquence d’apparition de chaque mot dans ce document.
- Le vecteur a donc autant de dimensions que de mots dans le vocabulaire.
Exemple concret :
Considérons deux documents :
- Doc 1 : « Le chat mange une souris. »
- Doc 2 : « Le chien mange une os. »
Le vocabulaire commun est : [le, chat, mange, une, souris, chien, os]
La représentation BoW sera :
| Mot | Doc 1 | Doc 2 |
|---|---|---|
| le | 1 | 1 |
| chat | 1 | 0 |
| mange | 1 | 1 |
| une | 1 | 1 |
| souris | 1 | 0 |
| chien | 0 | 1 |
| os | 0 | 1 |
Ainsi, Doc 1 est représenté par le vecteur [1, 1, 1, 1, 1, 0, 0] et Doc 2 par [1, 0, 1, 1, 0, 1, 1].
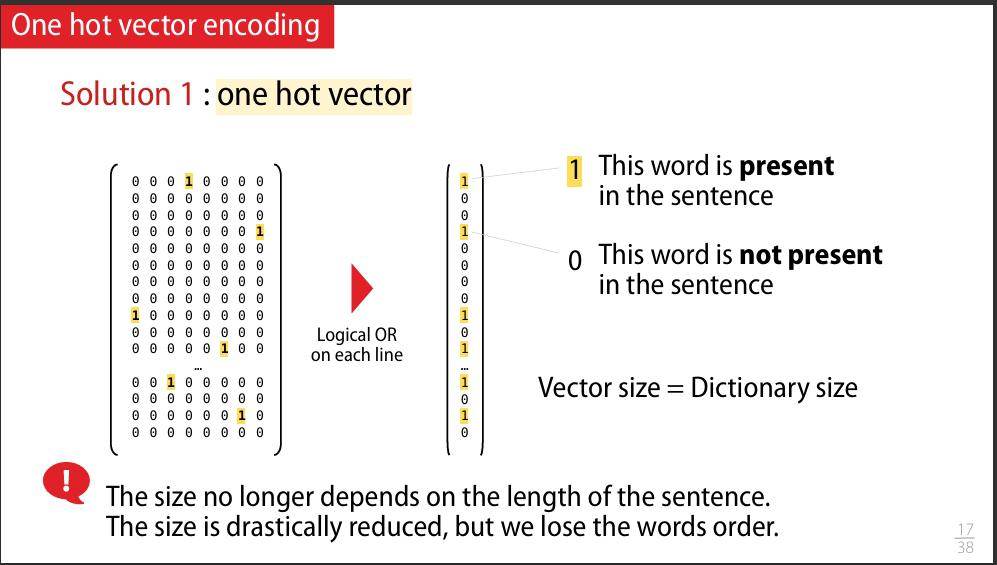
Figure : Schéma du processus de tokenisation Bag of Word
b. TF-IDF (Term Frequency – Inverse Document Frequency)
Le modèle TF-IDF est une amélioration du Bag of Words. Il ne se contente pas de compter les mots, il les pondère intelligemment : il donne plus d’importance aux mots rares (souvent plus informatifs) et moins à ceux qu’on retrouve partout (« le », « est », « de », etc.).
Bon… je sais, ça peut commencer à sentir fort les maths, mais reste avec moi ! Tu verras, c’est pas la mer à boire.
Comment ça fonctionne ?
- TF = Term Frequency → fréquence d’un mot dans un document.
- IDF = Inverse Document Frequency → inverse de la fréquence du mot dans toute la collection de documents.
La formule magique, c’est :
TF-IDF(t, d) = TF(t, d) × log(N / DF(t))
- t = le terme (mot)
- d = le document
- N = nombre total de documents
- DF(t) = nombre de documents contenant le mot
Dit autrement : un mot est important s’il est fréquent dans ce document mais rare dans les autres. C’est logique : le mot “chat” sera bien plus révélateur dans un texte de biologie que “le” ou “est”.
Exemple simple (avec 3 documents)
Soit 3 phrases :
- Doc1 : « Le chat dort. »
- Doc2 : « Le chien dort. »
- Doc3 : « Le poisson nage. »
Prenons le mot chat :
- Il apparaît dans Doc1 → TF = 1
- Il n’apparaît pas dans Doc2 ni Doc3 → DF(chat) = 1
- N = 3 documents → IDF(chat) = log(3 / 1) = log(3) ≈ 0.477
Donc : TF-IDF(chat, Doc1) = 1 × 0.477 = 0.477
Et dans les autres documents ? TF = 0, donc TF-IDF = 0. Logique !
c. Word Embeddings (Word2Vec, GloVe)
Avec les Word Embeddings, on entre dans une nouvelle ère du NLP : celle où les mots ne sont plus de simples occurrences à compter, mais des entités plongées dans un espace sémantique.
L’idée est simple et géniale : on représente chaque mot par un vecteur dense (typiquement de 100 à 300 dimensions) tel que les mots proches en sens soient proches dans cet espace vectoriel.
Parmi les techniques les plus célèbres : Word2Vec (Google, 2013), GloVe (Stanford), FastText (Meta). Ici, nous allons nous concentrer sur Word2Vec, et plus précisément sur son architecture CBOW.
c.1- Word2Vec — CBOW (Continuous Bag of Words)
Le modèle CBOW tente de prédire un mot à partir de son contexte. Il fonctionne comme un petit jeu :
Au fil de l’entraînement, le modèle ajuste les vecteurs de chaque mot pour que ceux qui apparaissent dans les mêmes contextes aient des vecteurs similaires.
Illustration schématique
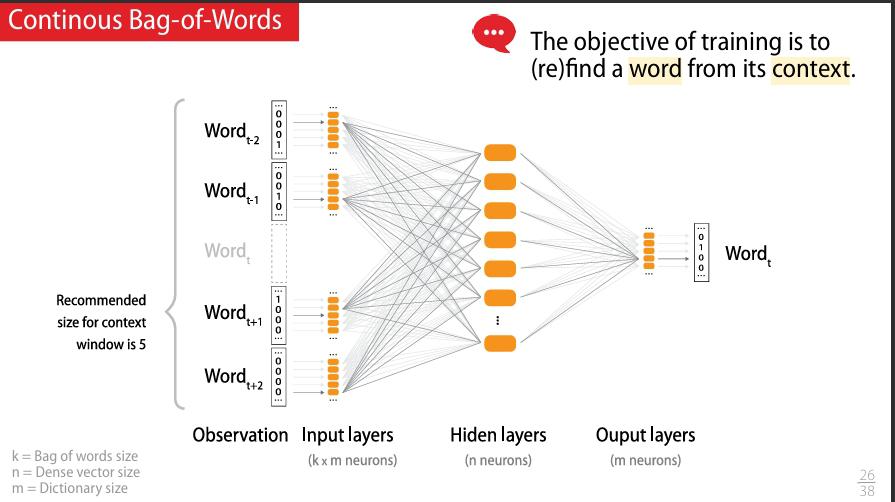
Figure : Architecture CBOW — prédiction du mot central à partir des mots du contexte
c.2- Word2Vec — Skip-Gram
Contrairement au CBOW, le modèle Skip-Gram fait l’inverse : il prend un mot central et essaie de prédire les mots du contexte. C’est un peu comme si, en entendant le mot « fromage », tu devais deviner que le reste de la phrase parle de « baguette », « vin » ou « odeur forte ».
Le Skip-Gram est particulièrement efficace pour apprendre des bonnes représentations de mots rares, car il génère plus d'exemples d’entraînement à partir de chaque mot cible.
Illustration
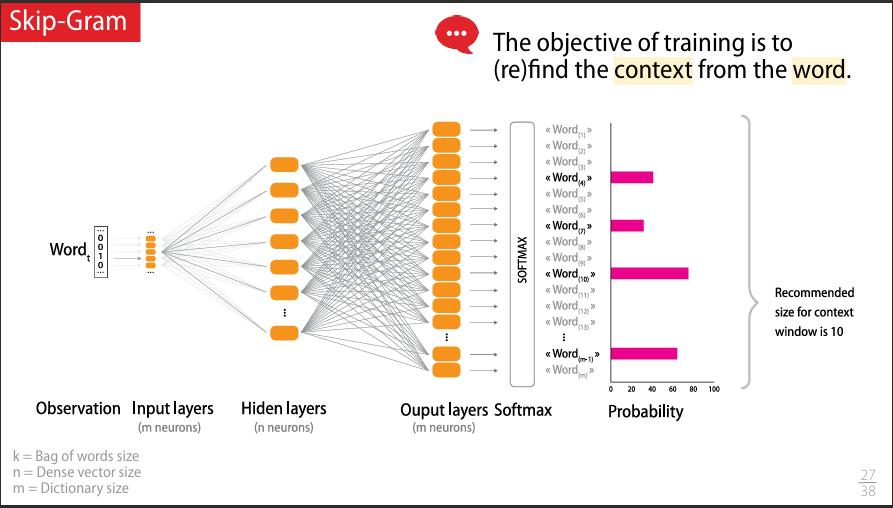
Figure : Architecture Skip-Gram — prédiction des mots du contexte à partir du mot central
c.3- Et les autres ?
- GloVe : (Global Vectors) basé sur la co-occurrence globale dans le corpus
- FastText : prend en compte les sous-mots → utile pour les langues morphologiquement riches
4. Attention is All You Need
Malgré leur utilité, les embeddings classiques comme Word2Vec ont une faiblesse : ils donnent la même représentation à un mot, quel que soit son contexte. Par exemple, « banque » a le même vecteur dans « banque de données » et « aller à la banque ».
Les modèles contextuels résolvent ce problème. Grâce au mécanisme d’attention introduit par le célèbre article Attention Is All You Need (Vaswani et al., 2017), chaque mot est représenté dynamiquement en fonction de son entourage. C’est le principe des modèles comme BERT, GPT ou T5.
a. Comprendre le mécanisme d’attention
Le mécanisme d’attention est une technique clé qui permet aux modèles de NLP modernes de se concentrer sur les parties les plus importantes d’un texte, un peu comme si vous lisiez un document en surlignant ce qui compte vraiment.
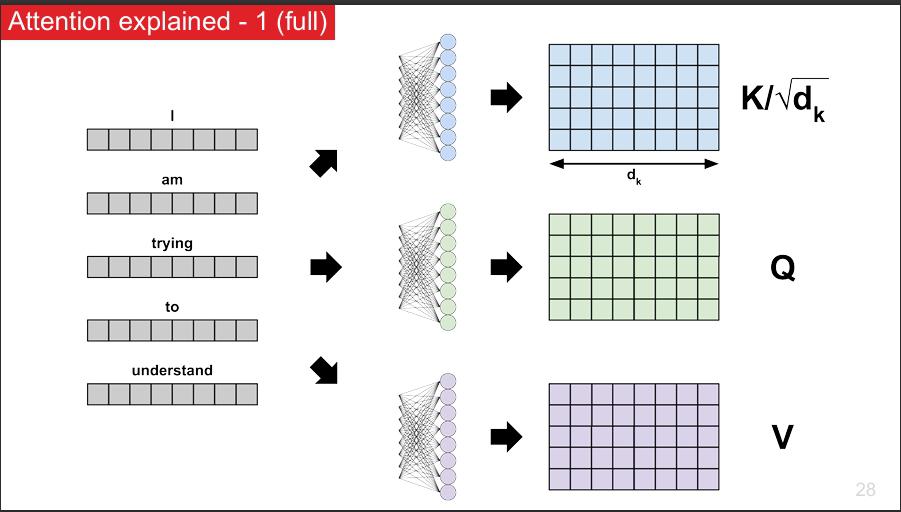

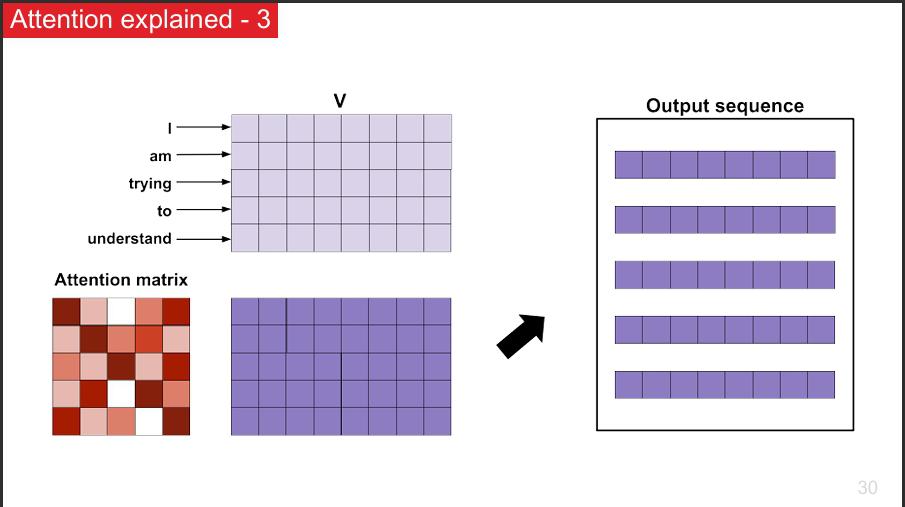
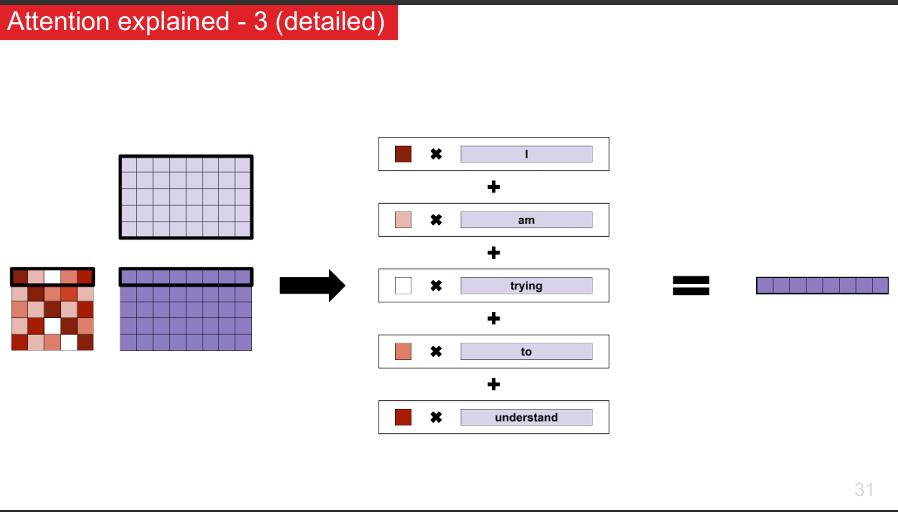
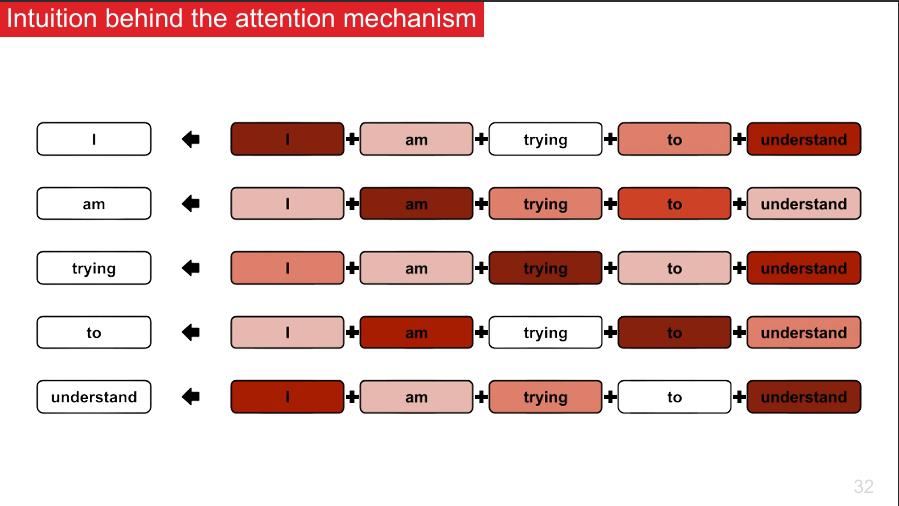
Ce mécanisme permet de mieux capter les relations entre mots, même distants, améliorant ainsi la compréhension fine du texte par le modèle.
Ces modèles permettent des compréhensions très fines du langage, jusqu’à générer du texte, traduire, résumer ou même coder.
Et maintenant ? On peut passer à la partie application concrète des modèles, ou explorer comment ces vecteurs nourrissent les réseaux de neurones pour des tâches comme la classification, la génération, ou la traduction.
5. Applications concrètes du Traitement Automatique du Langage Naturel (NLP)
Le NLP ne se limite pas à des concepts théoriques. Il est au cœur d’innombrables solutions que nous utilisons quotidiennement, transformant la manière dont nous interagissons avec les machines et traitons l’information.
a. Assistants vocaux et chatbots
Siri, Alexa, Google Assistant, ou encore les chatbots sur les sites web utilisent le NLP pour comprendre vos questions, extraire l’intention, et générer des réponses pertinentes. Derrière ces interactions, des techniques comme la reconnaissance d’entités nommées, l’analyse syntaxique et la génération automatique de texte sont en action.
b. Analyse de sentiment
Les entreprises scrutent les réseaux sociaux, les avis clients et les forums grâce au NLP pour détecter les émotions, jugements ou tendances positives/négatives. Cela leur permet de mieux comprendre leur audience et d’ajuster leur stratégie marketing.
c. Traduction automatique
Google Translate, DeepL ou Microsoft Translator reposent sur des modèles NLP avancés pour traduire des textes d’une langue à une autre, souvent en temps réel. Les techniques de deep learning, notamment les Transformers, ont grandement amélioré la fluidité et la qualité des traductions.
d. Résumé automatique
Avec la masse d’information disponible, les outils de résumé automatique génèrent des synthèses pertinentes, permettant de gagner du temps et d’extraire l’essentiel rapidement.
e. Classification et détection de spam
Le NLP est utilisé pour trier les emails, détecter les spams, catégoriser des documents, ou encore filtrer les contenus inappropriés, grâce à des modèles capables d’identifier le contexte et la nature des textes.
f. Applications médicales
Dans le secteur de la santé, le NLP aide à analyser des notes cliniques, extraire des données importantes et faciliter la recherche documentaire, contribuant à un diagnostic plus rapide et précis.
Ces exemples ne représentent qu’une fraction des possibilités. Le NLP est un domaine en pleine expansion, au croisement de l’intelligence artificielle, des sciences cognitives et de la linguistique, avec un impact toujours plus fort dans nos vies numériques.
6.Limites, risques et enjeux éthiques du NLP
Malgré ses prouesses, le NLP n’est pas une technologie magique et comporte plusieurs limites et risques importants qu’il faut connaître et surveiller.
a. Hallucinations et erreurs
Les modèles, surtout les plus récents comme GPT, peuvent parfois « inventer » des informations — ce qu’on appelle des hallucinations. Cela signifie qu’ils génèrent des réponses plausibles mais incorrectes, ce qui peut être problématique, notamment dans des domaines sensibles comme la santé ou le droit.
b. Biais et discriminations
Ces systèmes apprennent sur des données collectées dans le monde réel, qui contiennent souvent des biais sociaux, culturels, voire sexistes ou racistes. Sans vigilance, ces biais peuvent être reproduits ou amplifiés, posant un vrai défi éthique et technique.
c. Vulnérabilité et usage malveillant
Le NLP peut être détourné pour produire de la désinformation, du spam sophistiqué, ou pour créer des deepfakes textuels. La lutte contre ces usages malveillants est un enjeu majeur pour la confiance dans les technologies.
d. Vigilance et responsabilité
Il est crucial d’accompagner le déploiement des outils NLP de mesures rigoureuses : validation humaine, audits de biais, transparence sur les données d’entraînement, et régulations adaptées. L’utilisateur et le développeur doivent rester vigilants, comprendre les limites, et ne pas confondre « intelligence » et simple traitement statistique.
e. Questions éthiques
L’éthique du NLP soulève plusieurs questions :
- Qui est responsable quand un système génère une information erronée ?
- Comment protéger la vie privée et les données sensibles utilisées pour entraîner ces modèles ?
- Comment garantir l’équité et éviter les discriminations involontaires ?
- Quelle place pour la transparence dans ces modèles souvent opaques ?
En somme, le NLP est une technologie puissante mais fragile : elle nécessite un usage prudent, éclairé et responsable pour éviter les pièges et maximiser ses bénéfices.
7. Conclusion : le NLP, une révolution en marche
Le traitement automatique du langage naturel a franchi des étapes impressionnantes, transformant profondément notre rapport au texte, à la parole, et à l’intelligence artificielle. De la tokenization aux modèles de dernière génération comme les Transformers, chaque avancée repousse les limites de la compréhension machine.
Mais derrière cette révolution technologique, se cachent des défis majeurs : maîtrise des biais, vigilance face aux hallucinations, et responsabilité éthique. En tant que professionnels et utilisateurs, notre rôle est d’accompagner ces technologies avec rigueur et sens critique.
Si vous souhaitez plonger dans ce domaine passionnant, gardez en tête que le NLP est autant une science qu’un art, mêlant linguistique, mathématiques et informatique. Apprenez, testez, expérimentez — et surtout, restez curieux !
Le futur du langage avec l’IA ne fait que commencer, et vous êtes au cœur de cette transformation.
Merci d’avoir lu cet article !
N’hésitez pas à laisser un commentaire pour partager vos questions ou expériences sur le NLP. Pour ne rien manquer de mes prochains contenus autour de l’intelligence artificielle et du développement, abonnez-vous et partagez cet article avec vos collègues et amis passionnés. Sur ce ceux, je vous laisse une petite video ou j'explique tout ceci de vive voix 😎🤖
Regarder la Vidéo
Voir aussi
Fokouo saadie Luciano
Étudiant en Data Science passionné par le Deep Learning et l'IA. Curieux et autodidacte, j'aime explorer les algorithmes, modèles et défis de l'intelligence artificielle. Objectif : contribuer à des projets innovants et repousser les limites de la tech.
No comments yet. Start a new discussion.