IREX - Présentation et démonstration de TXT-AI pour la recherche intelligente dans la documentation IREX
Découvrez comment TXT-AI, un outil open-source d’intelligence artificielle, rend la recherche dans la documentation IREX plus rapide et plus intelligente.
1. Introduction
2. Présentation de TXT-AI
3. Concepts IA utilisés
4. Installation et configuration
5. Résultats obtenus
6. Limites et perspectives
7. Conclusion
8. Illustration vidéo
9. Voir aussi
1. Introduction
Dans un contexte marqué par la croissance rapide des volumes de données numériques, l’accès rapide et précis à l’information constitue un enjeu majeur pour les organisations produisant une documentation technique abondante. À l’Institut du Retour d’Expérience (IREX), la recherche d’informations pertinentes dans une base documentaire volumineuse représente un véritable défi, les méthodes classiques basées sur les mots-clés montrant souvent leurs limites face à la richesse sémantique des contenus. Afin de répondre à cette problématique, l’outil open-source TXT-AI a été étudié et expérimenté pour la mise en place d’un moteur de recherche sémantique intelligent. Le présent article propose une présentation de cette solution, des concepts d’intelligence artificielle mobilisés, ainsi que des résultats obtenus à partir d’un échantillon de la documentation de l’IREX.
2. Présentation de TXT-AI
TXT-AI est un framework open-source développé par NeuralMagic et écrit en Python. Il permet de construire des moteurs de recherche sémantique et des applications intelligentes capables de comprendre le sens des phrases, et non simplement les mots qu’elles contiennent.
TXT-AI repose sur les modèles de langage modernes (transformers) pour générer des embeddings — des représentations numériques du sens des textes. Grâce à ces embeddings, il devient possible de comparer des phrases entre elles selon leur signification, même si elles n’emploient pas les mêmes mots.
- Indexation intelligente de documents textuels
- Recherche sémantique basée sur la similarité de sens
- Résumé automatique de textes
- Clustering et analyse de similarité
- Compatibilité avec les modèles Hugging Face Transformers
3. Concepts IA utilisés dans TXT-AI
- Embeddings vectoriels : chaque document ou phrase est converti en un vecteur numérique capturant sa signification.
- Recherche sémantique : comparaison basée sur le sens des phrases plutôt que sur les mots exacts.
- TF-IDF hybride : pondération des mots selon leur fréquence et leur importance.
- Fuzzy matching : tolérance aux fautes et aux variations linguistiques.
- Résumé automatique : génération d’extraits de texte synthétiques grâce au NLP.
Grâce à ces principes, le moteur peut comprendre qu’une requête comme « comment créer un DSM » correspond à « procédure de mise en place d’un DSM », même si les mots diffèrent.
4. Installation et configuration
a. Installation
Pour l'installer, on utilise cette commande via le terminal:
pip install txtai pypdfNote: Python doit être installé pour pouvoir executer la commande
b. Indexation du corpus documentaire
- Chargement de la documentation IREX au format PDF.
- Extraction automatique du texte page par page à l’aide de pypdf.
- Indexation des textes dans TXT-AI avec métadonnées (titre, numéro de page, lien vers le document).
- Sauvegarde de l’index IA pour accélérer les recherches futures.
# Chargement du PDF
pdf_path = "Accueil.pdf" # Chemin vers le fichier PDF
reader = PdfReader(pdf_path)
print("Document chargé avec", len(reader.pages), "pages.")
# . Extraction page par page
print("Extraction des pages du PDF...")
rows = []
for i, page in enumerate(reader.pages):
text = page.extract_text() or ""
text = text.strip()
if not text:
continue
# . Indexation avec métadonnées
rows.append({
"text": text,
"title": pdf_path,
"page": i + 1,
"link": f"{pdf_path}#page={i+1}"
})
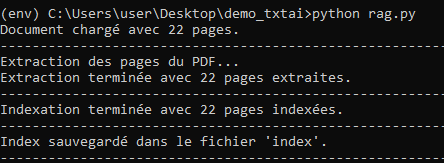
print("Extraction terminée avec", len(rows), "pages extraites.")# Création de l'index txtai
embeddings = Embeddings({
"content": True, # pour stocker les textes
"path": "sentence-transformers/all-MiniLM-L6-v2"
})
embeddings.index(rows)
print("Indexation terminée avec", len(rows), "pages indexées.")# Sauvegarde de l'index
embeddings.save("index")
print("Index sauvegardé dans le fichier 'index'.")Voici le resultat de l'indexation du corpus:
c. Exemple d’exécution
# Recherche
results = embeddings.search("comment créer un DSM")

Chaque résultat inclut un lien ouvrant directement la page correspondante du PDF IREX :
Accueil.pdf#page=5.
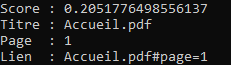
Ainsi, l’utilisateur accède immédiatement à la section concernée dans le document.
5. Résultats obtenus
- Les résultats sont pertinents même en cas de fautes de frappe.
- Le moteur comprend le contexte sémantique des requêtes.
- Les résumés automatiques aident à évaluer rapidement la pertinence du contenu.
- L’ouverture directe du PDF à la page concernée améliore considérablement l’expérience utilisateur.
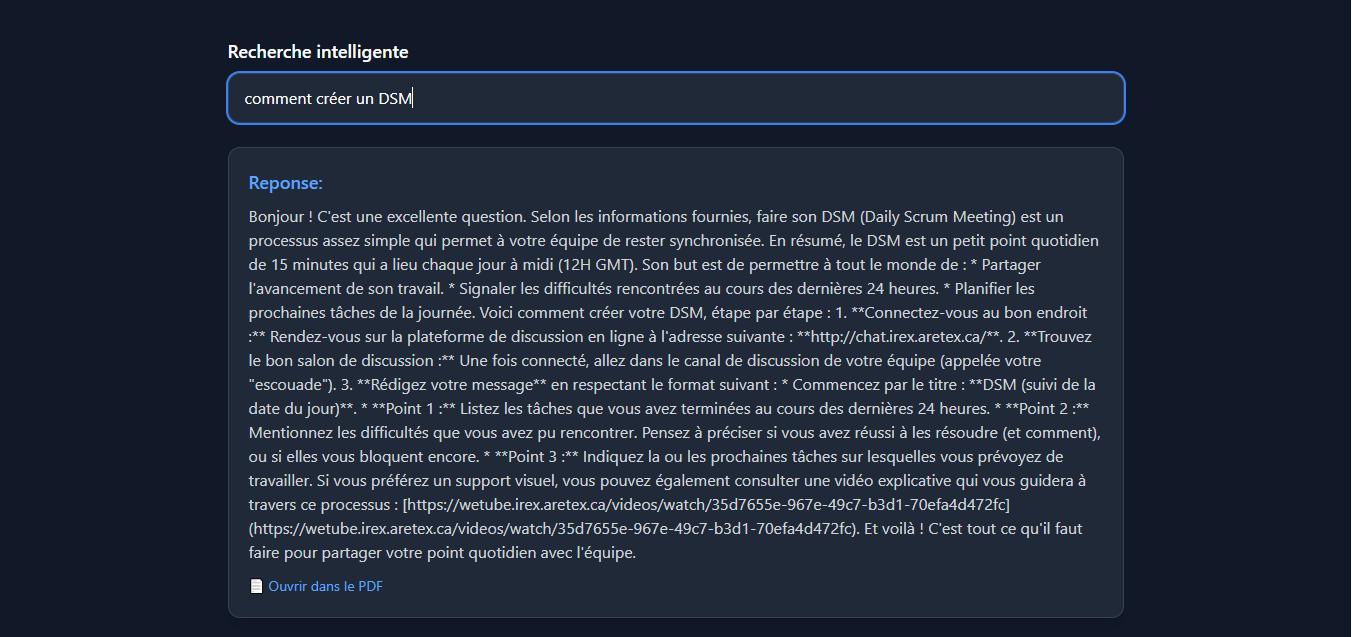
Requête : « comment créer un DSM »
→ Résultat : réponse à la question posée comme le montre la capture suivante »
6. Limites et perspectives
a. Limites actuelles :
- Indexation manuelle nécessaire du corpus documentaire.
- Modèles d’embeddings légers, moins performants que les grands modèles de langage (LLM).
- Pas encore d’intégration native avec MediaWiki.
b. Perspectives d’évolution :
- Intégration directe de TXT-AI dans l’interface documentaire IREX.
- Ajout d’un module de chat IA pour les questions conversationnelles.
- Utilisation de modèles RAG (Retrieval-Augmented Generation) pour enrichir les réponses.
- Déploiement sur un serveur interne (Docker / Nginx) pour usage collectif.
7. Conclusion
L’expérimentation de TXT-AI au sein de l’IREX démontre le potentiel de l’intelligence artificielle pour faciliter la recherche d’informations dans les bases documentaires internes.
En combinant embeddings, recherche sémantique et génération de résumés automatiques, la documentation devient plus vivante, plus accessible et plus utile.
TXT-AI constitue une base solide pour la construction d’un futur moteur de recherche intelligent au service de la diffusion du savoir au sein de l’Institut.
8. Illustration vidéo
Voici une vidéo qui illustre cet article :
No comments yet. Start a new discussion.